


Mistral Large, Groq, YOLO-World (AI Current #1)

The Current Wave
Mistral Large and Le Chat
Few models received such unanimously positive feedback than Mistral’s 7B and especially the Mixtral 8x7B. We also know Mistral Large — bigger, better, sexier — was in the works.
C'est arrivé! And boy it is good.
It is still not better than GPT-4, but Claude 2, Gemini Pro, and of course GPT-3.5 are now comfortably in the rear view mirror. See this MMLU (Massive Multitask Language Understanding) chart:
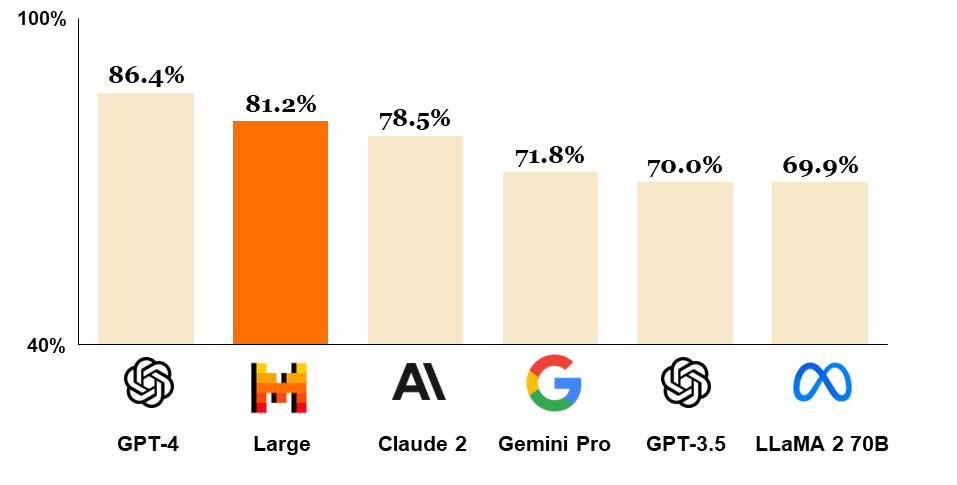
It comes with JSON format and function calling, and it is simply unbeatable when it comes to reasoning in French, Italian, German, and Spanish. You can try it yourself on Le Chat — yes, Mistral finally has its own frontend!
As far as I can tell, the only weakness of Mistral Large is the context window. 32k tokens is just not a lot, considering GPT-4 Turbo can handle 128k and the new, not yet publicly available Gemini Pro 1.5 a whopping 1 million. (Of course, Gemini Pro has other, really funny issues.)
Oh, and Mistral just partnered with Microsoft.
Groq is just silly fast
Nvidia is getting a challenger — and not from AMD or Intel, or from any of the traditional competitors. It’s a small, 200 people startup called Groq.
Let’s get two common misunderstandings out of the way. First, Groq is not a model; it’s a chip company. Second, it has absolutely nothing to do with Elon Musk’s Grok LLM.
The technical details of Groq’s new LPU — Language Processing Unit — are fascinating but out of the scope of this newsflash. For us with no PhD in semiconductors, I can offer an analogy. You can mine Bitcoin on a GPU. Heck, you can even mine Bitcoin on your phone. But for any economically justifiable performance, you need to use a machine specifically designed for the task, called ASIC — Application-Specific Integrated Circuit. Have you ever seen the photo of a Bitcoin farm? They are just containers, choke full of these ASICs.
Groq’s LPU is simply an ASIC designed specifically for LLMs. Nvidia cards are different: after all, they were developed to run Grand Theft Auto VI, not a Large Language Model. They can be used to run LLMs but… it’s just not the same.
In my comparison, Groq reached ~525 tokens per second on an essay writing prompt where the same Mixtral 8x7B model running on Nvidia infrastructure barely reached 170. That’s three times slower! The difference was even bigger with LLaMa-2-70B, where Groq was 3.9 times faster than Perplexity Lab’s Nvidia setup.
Your move, Jensen!
Stable Diffusion 3 is coming!
Not much is available about the new version of Stable Diffusion, except that it will be released very soon. Objectively, MidJourney is still way ahead of the rest, but I simply love SD. What sets it apart is how easy it is to work with it. No rate-limited APIs, no Discord shenanigans… just spin up a GPU instance, install it, and you are off to the races. This is why at work we’ve used SD 1.5 for the biggest generative AI + NFT gamification campaign in the world.
Anyway, make sure you sign up for the beta. I personally think SD 2.0 was outright bad, so v3 is a charm?

Gemma 2B and 7B released
Google is getting a ton of flak for all its blunders in AI, to the extent some people started comparing Sundar Pichai to Steve Ballmer — how mean 😅. But Gemma is cool.
Gemma is Google’s new open source model family coming in 7B and 2B flavors with a commercially permissive license. The 7B variant is performs somewhere on the level of Mistral 7B, better in some tasks, worse in others. But Gemma 2B might prove to be much more important.
A 2B model is small and fast enough to run not just offline but on a device with limited power like… a phone! We know Apple is working on local inference for the iPhone. Pixel next?
The Raft: Hands-on AI

There are many reasons to running AI models offline (on your own computer), such as privacy, data security, and, frankly, the sheer enjoyment of it. Sure, not everyone gets overly excited by a progress bar saying “Mistral 7B Instruct loading”, but if you are one of them (one of us!), you know exactly what I am talking about.
My preferred tool is LM Studio, which saved me hours of tinkering in the Terminal. It takes care of downloading models, offers a chat interface, and even comes with a built-in local inference server that aligns with OpenAI's API specifications. I recently tried it out with Google's Gemma 2B on my M1 MBP with 16GB of RAM, and the speed was more than satisfactory.
It is available for all platforms (Mac, Windows, Linux) and you can download it from here.
The Source: Repo of the Week
YOLO-World, the object detection tool incubated at Tencent AI Lab, just got an update with the release of a new model called X (not that X). It’s adds serious zero-shot capabilities to the already powerful YOLOv8 and it’s about 25-50 times faster than other open vocabulary detectors.
I gave it a try on Hugging Face and I’ve found that a lot depends on the configuration. Lower confidence thresholds seem to work much better, resulting in more accurate object recognition.
I was especially impressed by YOLO-World detecting the coffee cup in the third row on the shelf, although it mislabeled it as “bottle”. Still, very impressive.
